Repository와 Dao의 차이점에 대한 논쟁은 이전부터 끝없이 진행되어 왔다.
이번 포스팅에서는 Repository와 Dao의 차이에 대한 나의 생각을 논해보록한다.
필자가 생각하기에 Dao와 Repository의 차이점을 이해하기위해 필요한 선행지식은 다음과 같다.
1. 객체지향
2. DAO
3. DDD
4. 기본적인 웹 설계 구조
당연하다. DAO가 왜 그렇게 설계되었는지, 만들어진 목적을 이해하기 위해서는 객체지향적 설계법이 대한 지식이 수반되어야 한다. 또한 Repository를 이해하기 위해서는 DDD를 알아야 한다. 왜냐? DDD에서 Repository라는 개념이 튀어나왔기 때문이다.
실제로 스프링 프레임워크의 @Repository 어노테이션을 들어가서 보면 다음과 같이 명시되어 있다.
Indicates that an annotated class is a "Repository", originally defined by Domain-Driven Design (Evans, 2003) as "a mechanism for encapsulating storage, retrieval, and search behavior which emulates a collection of objects".
Dao란 무엇일까?
Dao(Data Access object)는 스프링의 아버지라 부를 수 있는 J2EE에서 등장한 개념이다.
에플리케이션을 사용하다보면 영구저장소 매커니즘이 필요할때가 매우 많아진다. 이때 영구저장소의 구현체는 정말 무수히 많다. 가장 간단하게 생각나는거만 Oracle, Mysql, MongoDB...
그렇다면 어플리케이션에서 영구저장소에 접근하기 위해서는 어떻게 하면 될까?, 정답은 각 영구 저장소 밴더에서 제공하는 API를 통해서 접근하면 된다.
하지만 이 방식의 문제점은 무엇일까?,
첫번째, 구현체와 로직이 너무 강한 결합을 가지게 된다.
만일 내가 영구 저장소를 Mysql을 쓰고 있었다고 가정해 보자. 이때 영구저장소를 Oracle로 바꿔야 한다는 요구사항이 들어왔다면, 우리는 Mysql의 API를 사용한 모든 구현을 변경해야 할 것이다. 즉, 변경에 자유롭지 않을 것이다(OCP위반)
두번째, 레이어가 깨진다.
일반적으로 웹 어플리케이션을 만들 때 우리는 레이어를 나눠서 설계를 진행한다.
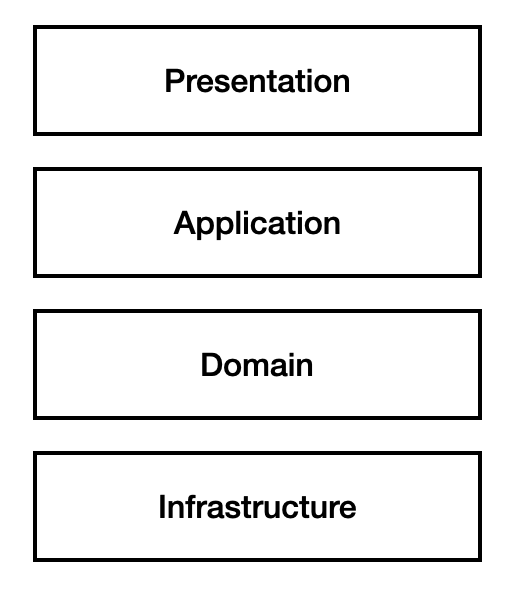
예시를 위해 일반적인 웹 어플리케이션의 아키텍쳐를 가지고 와 봤다. 어렵게 볼 필요 없다. 표현계층은 흔히 아는 view, 응용 계층은 service, 도메인은 비스니스 로직(도메인), infrastructure는 db, 외부 라이브러리... 등 어플리케이션을 만드는데 필요한 인프라 들을 의미한다.
흔히 퍼시스턴트 레이어라고 부르는게 인프라 스트럭쳐에 속해있다고 말할 수 있다.
이때, 우리의 예시에서 Mysql의 Api를 서비스 로직에서 사용하기 위해 Application계층에서 new 하여 생성했다고 가정해 보자. 이 순간 무슨일일 발생하는가? service로직을 담당하는 객체와 db와 관련된 api가 강한 결합을 가지며, 영속성과 관련된 로직이 서비스 로직에 생성된다. 즉, 인프라와 응용계층이 섞여 버리는 일이 발생한다.
세번째. 개발자의 러닝커브가 증가한다.
밴더마다 자신의 영구저장소의 API설계가 완전히 동일할 수는 없다. 회사마다, 그리고 그 특징마다 서로 다른 구현을 가질 것이다. 이는 새로운 밴더의 API를 사용할 때 마다 사용자에게 학습에 대한 부담을 증가시키며 러닝커브를 향상시킨다.
이런 문제점을 해결하기 위해 나온 패턴이 DAO 패턴이다. DAO는 밴더들의 API와 로직 사이에 있는 어뎁터와 같은 역할을 한다(어뎁터 패턴을 모른다면 한번 보고오길 바란다. 어뎁터 패턴을 이해해야지 이 문장을 이해할 수 있을것이다.).
먼저, DAO가 어뎁터의 역할을 수행함으로써 밴더들 사이의 구현의 차이점을 극복했다. 이를 통해 세번째 문제점을 해결할 수 있었다. 또한 이를 통해 얻을 수 있는 이점으로 강한 결합을 해결했다. 밴더의 구현체를 그대로 사용하는 것이 아니라 DAO라는 객체로 한번 더 감쌈으로서 내가 사용하는 데이터소스가 변경되더라도 그 로직에는 변화가 없도록 하였다. 이를 통해 첫번째, 세번째 문제점을 해결했다.
그러면 2번째 문제는 어떻게 해결했을까? 이는 DAO의 시퀀스 다이어그램을 보면 알 수 있다.
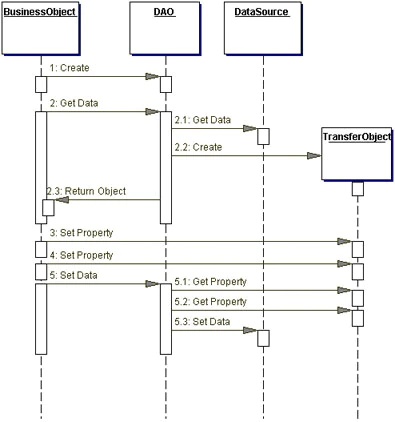
그림을 보면 데이터를 가지고 오는데 있어서 TransferObject를 사용하는것을 볼 수 있다. 이는 우리가 주로 말하는 DTO와 같은 개념이다(혹은 VO라고 알고있을 수 도 있다. 하지만 엄밀히 말하면 이런 계층간의 데이터이동을 위해 사용되는 객체는 TO 또는 DTO가 맞다. VO는 J2EE의 초판에서 TO를 부르던 말이며, 이는 후에 TO로 재명명 되었다. 또한 마틴파울러 또한 같은 개념을 제시했는데, 마틴파울러는 이러한 객체를 DTO라고 불렀다. 이때 마틴파울러는 VO라는 개념을 새롭게 제시하였다. 따라서 현재 우리가 VO라고 명명한다면 마틴파울러의 정의를 따라야 하는데, 이는 TO와는 전혀 다른 개념이므로 데이터 전송을 위한 객체를 VO라 부르는 것은 적절하지 않다.).
그렇다. J2EE에서는 데이터를 어플리케이션 layer로 전송하기 위해 TO를 사용했다. 이를 통해 레이어가 깨지는 것을 방지했다.
이때 우리는 명심해야 할 부분이 있다. DTO는 말 그대로 "데이터"를 전송하기 위한 객체이다. Entity 그 자체를 전송해서는 안된다. 여기서 하고싶은말이 무엇인고 하니, 가끔 구현들을 보면 DAO를 사용하는데 그 반환값으로 도메인객체(Entity)를 바로 내보내거나, DAO로 데이터를 저장하는데 Entity를 그대로 인수로 받는 경우가 있는데, 이는 완전히 잘못된 구현이다. 서로간의 레이어를 존중해야한다.
(보통 TO는 전송되는 쪽에 생성한다. 따라서 이번 경우 TO는 DataSource쪽 -인프라스트럭쳐 레이어- 에 속할 것 이고 이는 BuisniessObject -도메인, 어플리케이션 레이어- 가 DataSource가 존재하는 패키지에 의존한다는 것을 의미하기에 TO가 entity를 알아서는 안된다).
DAO가 영구저장소를 사용할 때 기존의 설계방식에서 발생하는 문제점을 어떻게 해결하였는지 이해 하였는가? 그리고 왜 DAO를 사용하는지 이해했는가? 그렇다면 Repository에 대해서 알아보도록 하자.
Repository란 무엇인가?
Repository는 DDD에서 처음 등장한 개념이다. 많은 사람들이 Repository를 객체의 컬렉션이라고 부른다. 왜 그렇게 부르는지 한번 확인해 보도록 하자.
일단 일반적인 웹 어플리케이션의 아키텍쳐를 다시 한번 보도록 하겠다.
Repository는 과연 어느 레이어에 속할까? 공부를 조금 한 사람들은 도메인이라고 말 할 것이다.
이상하다. 우리는 보통 Repository를 DB와 같은 영구저장소를 사용하기 위해 사용하는데, 왜 도메인 레이어에 속한다고 말하는 걸까?
일단 처음으로 돌아와서. 우리의 직관대로 생각해보자. Repository를 우리가 평소 사용하는 용도대로 생각해 보자, 그러면 이는 인프라스트럭처 레이어에 속해야 적당할 것이다.
원칙적으로 Repository는 객체의 상태를 관리하는 저장소이다. 즉, Entity(도메인 객체라고 생각하면 된다) 그 자체를 저장하고 불러오는 역할을 한다. 그러니 당연하게 Repository는 도메인레이어에 대한 지식을 알고 있어야 한다.
엄밀히 말하면 여기서의 Entity는 DDD의 애그리거트를 기준으로 한다. 이에 대해 설명하면 너무 설명이 비대해 질 것 같으니. 일단은 도메인 객체라고 생각하자...
그런데 생각해보라, 우리는 Repository를 인프라 스트럭처 레이어라고 정의했는데, 도메인의 정보를 알고 있어야 한다고? 그러면 도메인 레이어와 인프라스트럭처 레이어가 섞이는 것 아닌가???(즉, 계층이 깨진다)
여기서 부터 우리의 혼돈이 시작된 것이다.
정확히, Repository는 영구저장소를 의미하는게 아니다. 말 그대로, 객체의 상태를 관리하는 저장소일 뿐이다. 즉, Repository의 구현이 파일시스템으로 되든, 아니면 HashMap으로 구현됐든지 상관없다. 그냥 객체(entity)에 대한 CRUD를 수행할 수 있으면 된다.
Repository가 영구저장소라는 생각을 버려라. 그냥 컬랙션이라 생각해라. 우리가 HashMap을 사용하는데 이를 Infrastructure 레이어라고 생각하는가? 아니다. 그냥 그렇게 생각해라. 객체를 위한 컬렉션일 뿐이다.
컬렉션을 사용하는데 있어서 우리는 내부 구현을 신경쓰지 않는다. 그냥 그 퍼블릭 메소드만 확인하고, 제공해 주는 기능을 사용하면 된다.
이와같은 이유로 일반적으로 Repository의 인터페이스를 도메인 로직에 넣어둔다. 여기서 바로 Repository는 도메인 레이어라는 말이 나온것이다(명심하라, 인터페이스가 도메인 레이어다).
(살짝 말하자면, 어플리케이션 계층에 넣지 않는 이유는 계층구조를 깨트리지 않기 위함이다.).
하지만 Repository는 보통 서비스 로직에서 사용한다. 도메인 로직(비즈니스 로직)에서는 Repository를 사용하기 어렵고, 추천도 안한다. 그런데 왜 어플리케이션 레이어가 아니라 도메인 레이어라고 말할까? 이에대한 내용은 어그리거트, 모듈, 계층과 관련되어 있다. 하지만 이번 장은 DDD에 대한 내용이 아니므로 여기서는 생략하고 추후 따로 업로드 하도록 하겠다. 일단은 레포지토리는 도메인 레이어라는 사실만을 알아두라.
모듈은 고수준모듈에서 저수준 모듈에 의존하게 된다. 따라서 도메인 레이어에 속해있는 Repository를 Application레이어에서 사용하는건 전혀 어색하지 않다. 따라서 서비스로직에서 Repository의 인터페이스를 사용할 수 있게 된다.
그래, Repository는 영구저장소가 아니다는건 알겠다. 그런데 우리는 이를 영구저장소 처럼 사용한다. 이는 어떻게 된 것인가? 그 비밀은 바로, Repository의 구현체를 영구저장소 API를 이용해 구현한 것에 있다. 위에서 말했듯, Repository를 사용하는 클라이언트는 Repository가 어떻게 구현되어 있는지 모른다. 단지, 그 기능을 사용할 뿐이다. 하지만, 실제로 바인딩 되는 콘크리트 객체는 인프라 스트럭쳐 레이어에 속해 있는 것 이다.
그러면 또 계층이 섞이는게 아닌가 궁금할 것 이다. 하지만 이걸 생각해보라. 클라이언트는 Repository의 인터페이스만을 사용한다. 따라서 그 구현을 모른다고 말했다. DAO와 같다. 구현을 숨김으로써 로직을 한곳으로 응집시켰다(캡슐화). 따라서 서비스로직에서는 "도메인"의 레포지토리(컬렉션)을 사용한 것 뿐이다. 영속성과 관련된 로직은 전혀 모른다. 또한 인프라 스트럭처와 관련된 모듈 또한 전혀 import되지 않는다. 따라서 계층이 깨지는 일은 없다.
즉, 우리가 일반적으로 사용하는 관점에서 Repository의 Interface는 도메인 레이어, Repository의 구현체는 영속성 레이어에 속한다 이를 통해 도메인 레이어와 인프라스트럭처 레이어의 의존성이 뒤집힌다(DIP). 따라서 이젠 인프라스트럭처 레이어에서 도메인의 지식을 알아도 괜찮으며 이를 통해 Entity를 영속성 로직에 포함시킬 수 있게 되는 것 이다.
이제 결론을 내 보자.
간단하다. 둘을 너무나도 다르면서 비슷하다.
나는 이렇게 결론을 내고싶다.
DAO는 자신이 영속성객체라는것을 숨기지 않는다. 이름에서 그 의도를 바로 나타낸다. 자신이 인프라 스트럭쳐 레이어에 있다는 걸 숨기지 않는다. 또한 계층(모듈)의 의존성을 봤을 때 도메인이 인프라 스트럭쳐에 의존한다. 따라서 DAO를 이용해 바로 entity를 컨트롤 하는것은 계층을 무너트리고 잘못된 사용이다. 항상 DTO를 사용하여 데이터를 주고받아야 한다(같은 이유로 DTO에 Entity를 넣어서 보내는 행위 또한 안된다.)
그에 반해, Repository는 자신이 영속성 객체임을 숨긴다. 자신이 인프라 스트럭처 레이어에 있다는 것을 숨긴다. 또한 의존성이 역전되어 있기 때문에, entity를 그대로 가져와 영속성 로직을 수행하는 것을 가능하게 한다.
이 주제에 대해서는 논의가 많다. 사실, 개인적인 입장에서는 DAO를 사용하더라도 도메인 레이어에 속하는 Repository와 같은 interface를 이용하여 구현하면(데코레이팅) 충분히 Repository처럼 사용할 수 있다고 생각한다.
하지만 내 생각에서 가장 베스트는, 애초의 둘은 설계관점, 이용 목적부터 다르기때문에 혼용해서 사용하기 보다는 그냥 서로 목적에 맞게 사용하는게 최고일 듯 하다.
*잘못된 내용에 대한 피드백은 환영합니다 댓글로 남겨주세요 :)
제이슨의 피드백
DDD Layer는 없는 말이니 참고를...반영 완료DDD의 Repository는 단순히 Entity가 그 기준이 아닌 점반영 완료- 지금은 DAO나 Repository나 같다고 봐도 무방하고 현업의 코드들도 어쩌면 JpaRepository를 상속했다는 이유로 xxxRepository라고 명명한 것일 수도 있다는 점
- 그렇지만 Repository 클래스를 상속하기 때문에 xxxRepository라고 명명하는 것도 자연스럽다고 봅니다
- DDD의 Repository를 Repository답게 사용하는 일이 평생 없을 수도!
- 조금 더 다가가고 싶다면 Spring Data JDBC 사용을 고려해 볼 수도 있다.
댓글